

Efficient and Low-Latency Virtualization-based Fault Tolerance
1 Background
In recent years, as more and more applications in various fields are deployed on virtual servers in cloud platforms by default rather than on physical servers, availability has been regarded as one of the major factor to limit deploying more traditional applications on the cloud. Reliable service plays an important role in mission-critical applications, such as banking systems, stock exchange systems, and air traffic control systems, which cannot tolerate even a few minutes' downtime.
Obviously, reliable data centers need an effective and efficient failure recovery mechanism to prevent catastrophe. Hypervisor-based fault tolerance (HBFT), employing the checkpoint-recovery protocol, is a promising approach to sustaining mission-critical applications. HBFT works in the primary-backup mode. It capitalizes on the ability of the hypervisor or virtual machine monitor (VMM) to replicate the snapshot of the primary VM from one host (primary host) to another (backup host) every tens to hundreds of milliseconds. During each epoch (the time between checkpoints), hypervisor records the newly dirtied memory pages of the primary VM running on the primary host. At the end of each epoch, the incremental checkpoint (i.e., the newly dirtied pages, CPU state and device state) is transferred to update the state of the backup VM which resides in the backup host. When the primary VM fails, its backup VM will take over the service, continuing execution from the latest checkpoint.
However, the overhead of current HBFT systems is quite high during failure-free, especially for memory-intensive workloads. Moreover, HBFT systems usually introduce significant latency, which greatly restricts its application. In this article, the goal of our work is to build an efficient and Low-Latency Virtualization-based Fault Tolerance system. We have implemented two prototypes, Taiji and Phantasy. In the following, we will describe the details of the two systems.
2 Architecture

Fig. 2.1 The architecture of HBFT system.
Fig. 2.1 illustrates the architecture of HBFT system. The primary VM and the backup VM reside in separate physical hosts. Each host runs a hypervisor. Initially, the two VMs are synchronized by copying the state (i.e., all memory pages, CPU state and device state) of the primary VM to the backup VM. Then, the primary VM runs in repeated epoches by suspending/resuming its VCPUs. In each epoch, the primary hypervisor captures the incremental checkpoint (i.e., changed memory pages, CPU state and device state) of the primary VM and sends it to the backup host through Domain0. The output of the primary VM generated in each epoch is blocked in Domain0 until the acknowledgment of the checkpoint is received from the backup host. The hypervisor on the backup host (backup hypervisor) updates the state of the backup VM accordingly. Moreover, HBFT systems also need to control the “output commit” to ensure it can always provide a consistent view of the VM’s execution to the outside world even after failure. In practice, all outgoing network packets and disk writes are buffered until the transmission of this checkpoint is complete, which introduces significant latency. The poor performance can be ascribed to the long pause caused by generating the checkpoint and the numerous VM exits led by tracking dirty pages in the software layer.
3 Taiji: Efficient Hypervisor-based Fault Tolerance
To construct an efficient hypervisor-based fault tolerance system, we first introduce two optimizations, read-fault reduction and write-fault prediction, for the memory tracking mechanism. These two optimizations improve the performance by 31% and 21%, respectively, for some applications. Then, inspired by the advantages of superpage in operating systems, we present software superpage to map large memory regions between VMs. The approach accelerates the process of state replication at the end of each epoch significantly.
3.1 Read-Fault Reduction
In VM live migration, at the beginning of each pre-copy round, all the SPTs are destroyed. This causes the first access to any guest page to result in a shadow page fault and thus write accesses can be identified by the hypervisor. The side effect of this mechanism is that the first read access to any page also induces a shadow page fault, even though only write accesses need to be tracked. This mechanism has little effect on VM live migration since the whole migrating process takes only a few number of pre-copy rounds before completion.
However, for the HBFT system which runs in repeated checkpointing epochs (rounds) at frequent intervals during failure-free, the mechanism of the log dirty mode induces too much performance overhead. Through extensive experiments, we find that these overhead comes from frequent shadow page faults in each execution epoch because all the SPTs have been destroyed at the beginning of each epoch. Dealing with shadow page faults in virtualization environment incurs nontrivial performance degradation. Therefore, we propose an alternative implementation.

Fig. 3.1 Selectively check shadow page table entries by the marker and revoke write permissions at the beginning of each epoch.
In order to revoke write permissions efficiently, we use a bitmap marker for each SPT. Fig. 3.1 illustrates our mechanism. Each bit of the four-bit marker corresponds to one fourth of the L1 SPT and indicates whether there are writable entries in the segment. At the beginning of each epoch, we check the marker to identify segments with writable entries and only need to scan those segments to revoke their write permission. We then clear the corresponding bitmap in the maker to zero. During the period of execution, when a shadow page write-fault occurs, its associated bitmap is set according to the position of the shadow entry. Due to the fine spatial locality of most applications, those entries with writable permission tend to cluster together, making scanning process efficient. Thus, the paused period at the end of each epoch can be kept to an acceptable length.
3.2 Write-Fault Prediction
In order to track dirty pages, hypervisor intercepts write accesses by revoking the write permission of shadow entries. However, handling page faults incurs a nontrivial overhead. Therefore, we consider improving log dirty mode further by predicting which entries will be write accessed in an epoch and granting write permission in advance. When a shadow entry is predicted to be write accessed in the epoch, the page pointed to by this entry is marked as dirty, and the entry is granted with write permission, which will avoid shadow page write-fault if the page is indeed modified later. However, prediction errors will produce false "dirty" pages which consume more bandwidth to update the backup VM.
Based on the behavior of shadow entry write accesses analyzed in the previous section, we develop a prediction algorithm which is called Histase (history stride based) and relies on the regularity of the system execution (see [2] for more details).
3.3 Software Superpage
In the original design, at the end of each epoch, all the dirty pages have to be mapped into Domain0’s address space for read-only accesses before being sent to the backup VM through the network driver. The overhead of mapping/unmapping memory pages between VMs is rather large. Evidently, reducing the mapping/unmapping overhead can improve the performance of the primary VM significantly.

Fig. 3.2 Software superpage
Fig 3.2 illustrates the design details. Software-superpage, designed as a pseudo-persistent mapping, reduces the map/unmap overhead to a low level. Our design builds upon two assumptions. First, Dom0 (VMM) is non-malicious and can be granted with read-only access to the primary VM’s entire physical memory. Second, because of balloon driver or memory hotplug, a system’s memory pages may be changed.
The advantages of software-superpage are two-fold. On one hand, for fault tolerance daemon, it provides an illusion that all the memory pages of the primary VM are mapped into Dom0’s address space persistently. It eliminates almost all map/unmap overhead. On the other hand, it does little disturbance to the other parts residing in the same virtual address space of Dom0 because only a small part of virtual address space is actually used to access the entire memory pages of the primary VM.
3.4 Demo of Taiji
4 Asynchronous Dirty Page Prefetching
Moreover, HBFT systems usually introduce significant latency and non-negligible overhead, which greatly restricts its application. In this section, our main goal is to leverage the emerging processor and network features to build an efficient virtualization-based fault tolerance system with latency at least one order of magnitude less than the state-of-the-art systems without using these features.
To overcome these bottlenecks, we design and develop Phantasy, a system that keeps track of dirty pages using page-modification logging (PML) available in commodity Intel processors to reduce page tracking overhead, and asynchronously prefetches the dirty pages to shorten the sequential dependency of generating and transmitting checkpoints.
4.1 Limitations of Prior HBFT systems
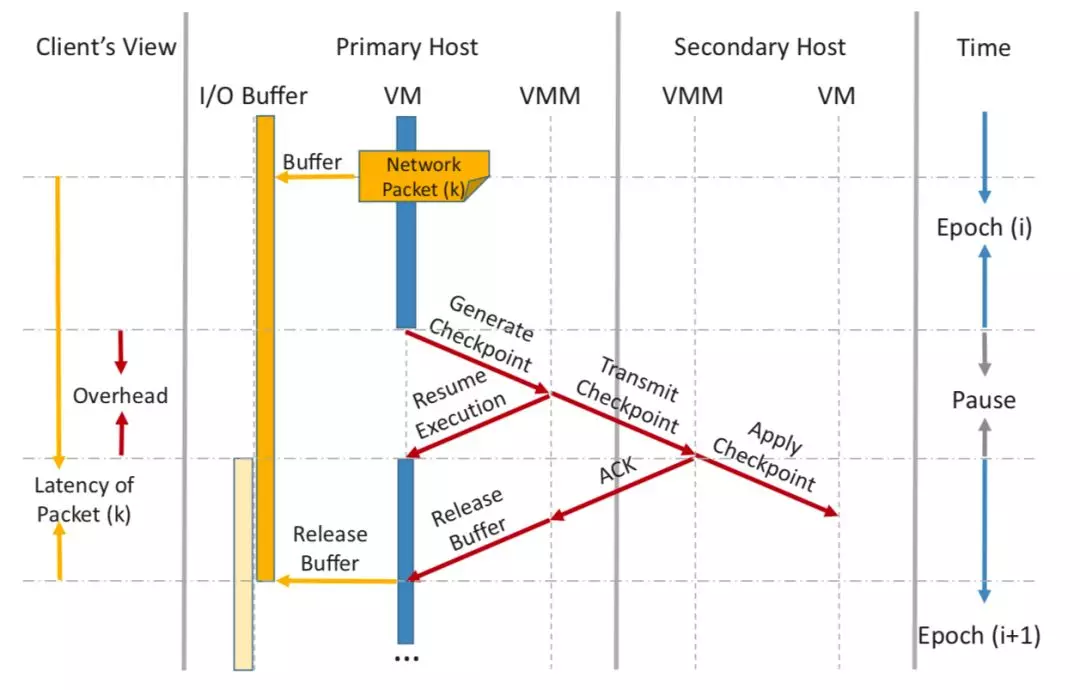
Fig. 4.1 The execution flow of prior HBFT systems
The HBFT systems achieve high availability by repeatedly replicating the entire system state of the primary VM to the secondary VM running on a backup host. Specifically, the primary VM takes incremental checkpoints including CPU, memory, and device states by executing the iterative pre-copy phase of live migration at a fixed frequency. Moreover, fault tolerance systems like Remus also need to control the “output commit” to ensure it can always provide a consistent view of the VM’s execution to the outside world even after failure. In practice, all outgoing network packets and disk writes are buffered until the transmission of this checkpoint is complete as illustrated in Fig. 4.1. For some mission-critical applications, the network latency introduced may be unacceptable since most of applications are delay-sensitive.
4.2 Asynchronous Dirty Page Prefetching
The key to overcome the limitations of prior works is the capability of asynchronously prefetching dirty pages in parallel with the primary VM execution to shorten the sequential dependency of constructing and transmitting the checkpoints. To realize this, we design a novel mechanism to prefetch the dirty pages without disrupting the primary VM execution. Phantasy leverages page-modification logging (PML) technology available on commodity processors to reduce the dirty page tracking overhead and asynchronously prefetches dirty pages through remote direct memory access (RDMA).

Fig. 4.2 Architecture of Phantasy.
We design Phantasy as illustrated in Fig. 4.2. Phantasy implements the fault tolerance as an extension to VMM, which provides a fault tolerant solution for the entire virtual machine and can take full advantage of the PML and RDMA. Phantasy introduces an asynchronous pull-based prefetching strategy to achieve efficient and low-latency virtualization-based fault tolerance. First, by leveraging the PML, Phantasy can directly and efficiently collect and log the page modification information without suspending the primary VM. Then, these page modification information is used to guide the secondary VMM to accurately prefetch the dirty pages from the primary VM’s memory directly through one-side RDMA READ operation. Fig. 4.3 illustrates the workflow of Phantasy (see [1] for more details).
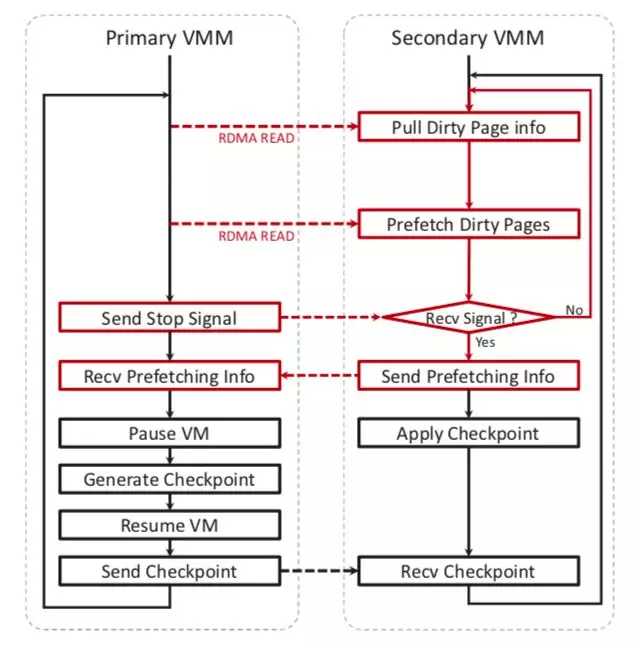
Fig 4.3 The workflow of Phantasy for asynchronously prefetching dirty pages to shorten the sequential dependency of constructing and transmitting checkpoints.
4.3 Demo of Phantasy
5 Conclusion
To realize practical efficient and low-latency fault tolerance in the virtualized environment, we first identify several bottlenecks in prior approaches, and then we introduce two HBFT systems, Taiji and Phantasy.
To develop an efficient HBFT system Taiji, we first analyze where the overhead comes from in a typical HBFT system. Then, we analyze memory accesses at the granularity of epochs. Finally, we present the design and implementation of the optimizations to HBFT, including: a) analyzing the behavior of shadow entry accesses, b) improving the log dirty mode of Xen with read fault reduction and write fault prediction, and c) designing software-superpage to map large memory region between VMs. The extensive evaluation shows that our optimizations improve the performance of the primary VM by a factor of 1.4 to 2.2 and the primary VM achieves about 60% of the performance of that of the native VM.
To develop low-latency virtualization-based fault tolerant system Phantasy, we have made the first attempt to leverage emerging processor (PML) and network (RDMA) features to achieve an efficient and low-latency fault tolerance solution. We shorten the sequential dependency in checkpointing execution by asynchronously prefetching dirty pages using a pulling model. By evaluating our system on 25 real-world applications, we demonstrate that Phantasy can significantly reduce the latency by 85%.
Publications
[1] Shiru Ren, Yunqi Zhang, Lichen Pan, and Zhen Xiao. Phantasy: Low-Latency Virtualization-based Fault Tolerance via Asynchronous Prefetching IEEE Transactions on Computers (TC), February 2019.
[2] Jun Zhu, Zhefu Jiang, Zhen Xiao, and Xiaoming Li. Optimizing the Performance of Virtual Machine Synchronization for Fault Tolerance IEEE Transactions on Computers (TC), December 2011.
[3] Jun Zhu, Zhefu Jiang, and Zhen Xiao. Twinkle: A Fast Resource Provisioning Mechanism for Internet Services Proc. of IEEE Infocom, April 2011.
Click to view all publications of our lab
Talks
Twinkle: A Fast Resource Provisioning Mechanism for Internet Services. IEEE Infocom, Shanghai, China, April 2011.
Click to view all talks of our lab