

跨编程语言分布式机器学习框架研究
1 摘要
随着互联网的发展,研究人员能够获取到越来越多的数据,单机训练方法难以满足研究人员快速高效训练模型的需求,因此分布式机器学习框架成为了当下的主流选择。现有的主流机器学习框架包括TensorFlow,PyTorch,Petuum等,如果使用以上框架,研究人员需要学习目标框架的编程语言,然后根据该框架的接口重新编写机器学习代码。现有的机器学习框架都存在跨编程语言的问题,用户为了使用这些训练框架需要重新学习一门新的编程语言,这带来了高昂的开发代价;现有的机器学习训练框架大多采用检查点机制进行故障恢复,因此在容错方面以及集群动态扩展方面还有明显的提升空间。
基于现有机器学习框架的不足,本文提出一种高可用的跨编程语言的分布式机器学习训练框架Plug-in ML。该框架基于参数服务器架构,使用进程间通信方式与原有单机机器学习程序交换模型参数;此外,本框架兼容任何的编程语言,可以使用原有的单机机器学习程序与本框架对接,显著降低了研究人员的使用门槛,另外还支持动态的增加和删除训练节点,提供用户透明的网络通信方式、支持可配置的模型同步方式以及具有完备的容错机制。
研究表明,通过增加简单的交互代码,任何编程语言都可以利用该框架将原有的单机迭代式机器学习程序,扩展为分布式机器学习程序。实验结果表明,与单机训练方式相比,Plug-in ML能够达到与其相同的训练效果,同时,还具有良好的扩展性,能够达到近似线性的加速比;与现有的分布式机器学习框架相比,Plug-in ML框架只有很少的系统开销。
2 系统架构

图 2.1 Plug-in ML系统架构图
本系统分为五个模块,分别是参数服务器(Server)模块、代理(Agent)模块、控制(Master)模块、通道(Channel)模块和用户(User)模块。参数服务器模块负责机器学习模型的存储、模型合并、参数的备份和模型的导出;代理模块负责与参数服务器模块和用户模块交互模型,为用户提供透明的网络通信;控制模块负责集群的启动,动态的增删节点,集群容错控制;通道模块定义了用户和本框架的交互模型;用户模块是用户提供的机器学习脚本。
本框架包括多个Master节点、多个Server节点和多个Agent节点,其中Agent节点只和Server节点及Master节点通信,Agent节点之间不通信。每个Server节点存储一部分模型,所有Server节点的参数组成完整的模型。每个Agent节点存储一部分训练数据,绑定一个用户提供的机器学习脚本,计算本地的参数更新量比如梯度。Master节点记录Server节点和Agent节点信息以及机器学习任务相关的信息。
本框架提出的容错方案分为三部分:Master节点的容错,Server节点的容错,Agent节点的容错。相较于其他机器学习系统的单个Master节点设计,本系统采用多个Master节点组成一个主备Master集群,保证Master出现单点故障的情况下依然能够处理集群的状态以及外部的请求。工程实践中常见的故障是硬件故障。美国卡耐基梅隆大学的一项研究通过对22个高性能计算系统9年间的全部错误统计表明,在错误数量方面,硬件错误的占比最高,约占全部错误数量的65%。由于硬件错误造成的系统停机时间约占总停机时间的60%。硬件错误的特点是错误发生后,系统立刻停止运行,即所谓的fail stop,比如电源故障(power failure)就属于典型的硬件故障。硬件错误一般是独立发生的,可以认为多台Master节点同时故障的概率极小。采用分布式一致性哈希和参数备份的方式完成Server节点的容错,提供延迟恢复的策略。由于Agent节点是无状态的并且不依赖也不影响其他的节点,因此本系统采用重新启动的方法完成Agent节点的故障恢复。
图2.1 展示了Plug-in ML系统的宏观架构。图片中的长虚线表示集群的控制信号,当上方的Master节点发生故障之后,所有节点切换到下方的Master节点;黑色实线表示Server节点之间的参数备份和同步;短虚线表示Agent节点和Server节点之间的参数更新。
3 故障恢复
故障恢复是分布式系统领域重点研究的问题,也是本框架在现有机器学习框架之上的一次尝试与创新。3.1节详细描述本框架的系统架构和设计原理。本小节将从系统的各个模块的角度详细的阐述系统故障恢复的流程。
3.1 控制节点故障恢复
Plug-in ML框架的控制节点(Master节点)有多个备份节点,所有的Master节点中只有一个节点,称为Lead Master节点,监听和记录集群的工作状态,其他的Master节点都是Lead Master节点的备份,同样记录着集群的工作状态,但是并不能发送集群的控制信号。控制节点的系统架构在3.1.4节有详细的叙述,下面将分两类情况讨论Master节点故障的问题:
非Lead Master节点故障。当非Lead Master节点发生故障之后,Lead Master节点会检测到该节点的心跳超时,于是Lead Master节点选择一个可用的节点重新开启一个Master进程,新开启的Master进程尝试竞选Lead Master,但是发现Zookeeper集群中已经存在一个Lead Master节点,于是该Master节点选择成为Lead Master节点的备份节点,从Lead Master节点同步集群状态信息,向Lead Master节点汇报心跳,同时在检测到Lead Master节点超时之后尝试竞选Lead Master。在检测到Master节点故障之后,Lead Master节点会在发送给 Agent节点和Server节点的心跳信息中附加集群状态改变信息,即删除故障Master节点,Agent节点和Server节点接收到该消息之后更新本地的集群状态信息。
Lead Master节点故障。当Lead Master节点故障之后,所有的Master节点都参与竞选Lead Master过程,最终成为Lead Master的节点将更新集群配置信息,并将最新的集群状态发送给Agent节点和Server节点,Agent节点和Server节点之后将心跳信息发送给新的Lead Master。
3.2 参数服务器节点故障恢复
参数服务器节点(Server节点)担负着存储模型和更新模型的任务,如果参数服务器节点在训练的过程中发生故障,那么必须重新训练模型。由于海量的训练数据和超大规模的模型,导致模型训练时间增长到天的级别,这意味着在训练过程中机器故障无法避免,而且重新训练模型有着高昂的代价。本小节重点阐述本框架增加参数服务器节点和移除参数服务器节点的背后运行机制。
移除参数服务器节点。当参数服务器节点发生故障,Lead Master节点需要通知其他节点集群状态的变化,例如通知Agent节点不能再向该参数服务器节点获取和更新参数,通知Master节点该参数服务器节点已经从系统移除,通知其他的参数服务器节点同步和更新模型。在Server节点故障之后,Lead Master节点将接收不到该节点的心跳,于是Lead Master更新模型的参数划分,然后将新的参数划发送给整个集群;Server节点检测到其维护的模型和备份的模型都发生了改变,于是Server节点向其需要备份的Server节点发送参数请求获取最新的参数;Agent节点更新参数划分方法为了能够根据参数的index找到合适的Server节点。至此,移除Server节点完成,其中包括Master节点更新集群状态、Agent节点更新参数划分、Server节点完成参数备份。
增加参数服务器节点。Lead Master选择一个合适的节点启动Server进程并将全局参数划分一份给新启动的Server节点,新启动的Server节点向其他Server节点请求模型参数;等待新启动的Server节点完成模型请求之后,Lead Master节点向整个集群广播Server增加消息同时把集群状态写入Zookeeper集群保存,Server节点收到增加Server节点请求之后调整该节点存放的参数,Agent节点收到消息后更新参数划分表并与新Server节点建立连接。
所谓参数服务器集群的故障恢复工作就是移除故障服务器并添加参数服务器的过程。Lead Master节点检测到Server节点故障,进入移除参数服务器阶段,在此阶段中Lead Master会抑制Agent节点请求和更新模型,移除完成之后,Agent节点和Server节点重新工作;Lead Master节点检测有无可用资源,如果满足资源要求则Lead Master节点尝试增加参数服务器节点,同样在这个阶段中Lead Master抑制Agent节点请求和更新模型。
3.3 代理节点故障恢复
由于机器故障或者其他进程的干扰,代理节点(Agent节点)也可能发生故障。与参数服务器故障恢复类似,代理节点的故障恢复也由两部分组成,移除代理节点和增加代理节点。移除和增加代理节点代价都低于Server节点的故障恢复,因为Agent节点不需要保存模型状态信息。 移除代理节点。在检测到Agent节点心跳超时之后,Lead Master节点更新集群状态信息并发送给Server节点,因为使用BSP协议更新模型时Server节点需要明确的知道系统中Agent节点的数量。 增加代理节点。Lead Master选择合适的节点启动Agent进程并将当前机器学习的任务信息发送给Agent进程,其中包括训练数据路径和当前迭代轮次,然后在收到Agent进程的确认消息之后将增加Agent节点的消息广播到整个集群。
4 系统测试
4.1 系统加速比测试
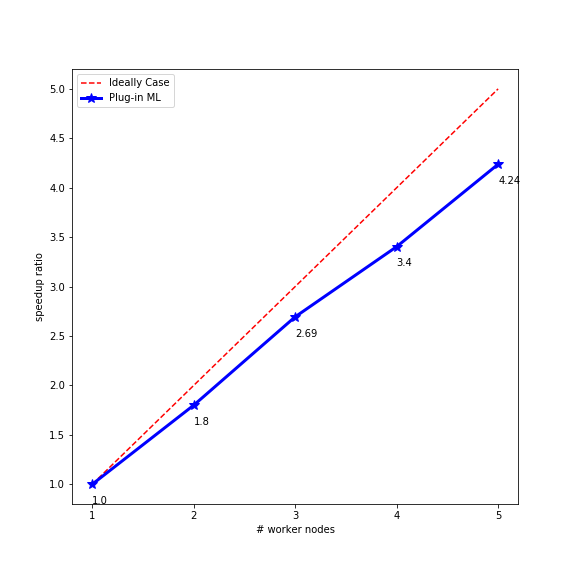
图 4.1 系统加速比。蓝色折线表示Plug-in ML系统的加速比,红色虚线为辅助曲线
加速比实验用来测试Plug-in ML的扩展性。该实验用来测试将原有的机器学习程序通过Plug-in ML框架扩展成多台机器训练时的加速比,所谓加速比就是单机训练用时与多台机器的训练用时的比值。训练用时是指机器学习模型在验证集上的误差达到最低且收敛的时候所花费的时间。图4.1 展示了Plug-in ML框架的加速比,通过红色的辅助虚线可以近似看出该框架在分布式训练下能够达到近似线性的加速比。不过,通过该图也能够看出,当集群的节点数量增加时系统的开销也会缓慢的增大,这是由于随着集群中的机器存在着差异,比如某些机器的计算力比较低,或者机器增加之后,系统的不稳定性也在增大,因此该框架的开销也会相应的增大。
4.2 系统正确性验证
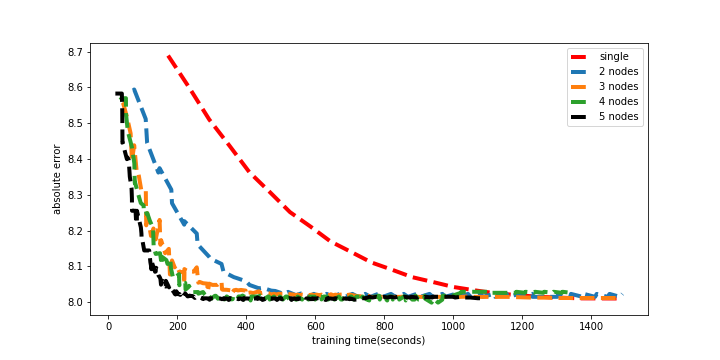
图 4.2 正确性实验
正确性实验用来验证,在分布式训练下模型依然能够达到单机训练的结果。图4.2 展示了Plug-in ML框架在1-5台机器下验证集误差的变化曲线,从该图可以看出,在分布式训练时模型也收敛到和单机训练相同的误差。并且可以看到当训练时间比较久之后,模型出现了轻微的过拟合。
图4.2中从右到左依次表示使用1-5台机器进行训练的绝对误差曲线。其中使用一台机器训练的时候单机代码并没有与Plug-in ML框架进行通信,也就是该曲线为原有的机器学习代码执行过程中的绝对误差曲线。
5 总结展望
本课题用于解决实际研发过程中随着数据量的增大将单机程序扩展为分布式程序的需求。为了解决多编程语言单机代码的兼容性问题,本论文提出了与编程语言无关的编程模型。为了方便用户使用减少学习和开发代价,本框架提供了简单易学的编程接口。相较于其他分布式机器学习系统,本框架提供了高效的故障恢复方法。为了优化模型同步开销,本框架实现了ASP,BSP,SSP和Drop方法供用户选择。通过实验结果可以确定:通过Plug-in ML框架,研究人员可以很容易地将原有的单机机器学习代码扩展成分布式机器学习代码。Plug-in ML框架能够达到近似线性的加速比。在完成以上功能的同时,Plug-in ML框架提供了良好的容错性能和高可用性。
通过Plug-in ML框架的实验发现,随着集群的增大模型同步造成的开销逐步占据更大的比重。同时随着数据集的扩张,分布式模型更新协议将变得越来越重要。本项工作试验过同步更新协议异步更新协议,而且发现在多数情况下异步更新策略并不能达到理想的效果。这促使Plug-in ML系统在实验阶段采用的同步更新协议。因此如何平衡快慢节点即舍弃掉部分计算力低下的计算节点依然是未来研究的热点。
相关成果
专利
一种插件式分布式机器学习计算框架及其数据处理方法 发明人:郑培凯、马超、倪焱、肖臻,专利号:201810004566.X,申请时间:2018年1月3日
一种面向大规模机器学习系统的机器学习模型训练方法 发明人:张正超、倪焱、郑培凯、马超、肖臻,专利号:201811000167.2,申请时间:2018年8月30日
一种高可用分布式机器学习计算框架的容错方法和系统 发明人:郑培凯、李真、张晨滨、宋煦、肖臻,专利号:201910159918.3,申请时间:2019年3月4日
软件著作权
软件全称:高可用“插件式”分布式机器学习系统V1.0 登记号:2019SR0420534 著作权人:北京大学 登记日期:2019年3月1日