

基于深度强化学习的集群资源调度算法研究
1 摘要
集群资源调度是分布式系统里的核心技术,也是当前系统领域的研究热点。目前的资源调度算法主要靠研究人员手工设计启发式算法,然后在实际的系统中迭代测试。然而,这样的开 发模式费时费力,并且由于调度问题的复杂性,人工设计的启发式算法不一定能够获得很好的调度效果。
近年来,强化学习在游戏、自动驾驶等序列决策任务上取得了一系列令人瞩目的成就。与人类的学习过程类似,强化学习通过与环境进行不断交互,根据环境的反馈来改进自己的行为,从而进行策略优化。而集群调度算法决定将当前可用资源以何种方式分配给待调度的任务,是一个典型的序列决策问题,可以使用强化学习进行训练优化。本课题的研究目标是将深度强化学习技术应用到集群调度领域,通过定义奖励函数自适应地学习出比人工设计更好的调度算法,当环境发生变化时,只需要重新学习就可以适应新环境,大大提高调度效率。
实验结果表明,本课题针对批处理任务所实现的调度算法有很好的可扩展性,可以支持集群规模的动态变化;针对流计算任务所实现的资源管理算法可以进行细粒度的资源管理,同时取得较快的决策速度。两个资源管理算法在多项重要指标上都取得了优于传统启发式算法的性能。
2 算法设计
2.1 批处理任务资源调度算法
针对批处理任务的资源管理算法使用了资源快照的表示方法,可以支持任意粒度的资源分配,大大压缩了状态维度,具有良好的可扩展性。本课题提出基于卷积神经网络、残差连接、并联支路的特征提取网络,可以高效地对资源快照进行深层次的特征提取和抽象,提高了智能体的学习能力。强化学习奖励的设置取决于应用的优化目标,比如以平均任务延迟或平均任务完成时间为优化目标,那么每次调度不成功(找不到可以满足任务需求的计算机),就给予一定的惩罚。
本项目的一个亮点在于对任务偏好的支持。大规模集群中的计算机可能是异构的,不同计算机的硬件设备可能有差异。本项目采用Kubernetes里打标签的方式来支持任务偏好。每台计算机可以标注一些属性,比如是否有固态硬盘,CPU核数等。每个任务也有偏好标签,表示对不同机器属性的偏好程度。这些偏好需要根据应用的特点手工定义,然后通过特征嵌入的方法映射到低维空间,作为特征提取网络的输入。
本项目提出了基于双智能体的资源调度模型。双智能体模型从任务调度顺序和任务装箱两个角度出发,同时考虑当前时刻应该选择哪些任务部署到哪些机器上。我们用<机器,任务>这样的二元组来表示可能的调度决策,这样每次调度时需要从所有可能的二元组中选出一个子集来做为实际的调度动作。
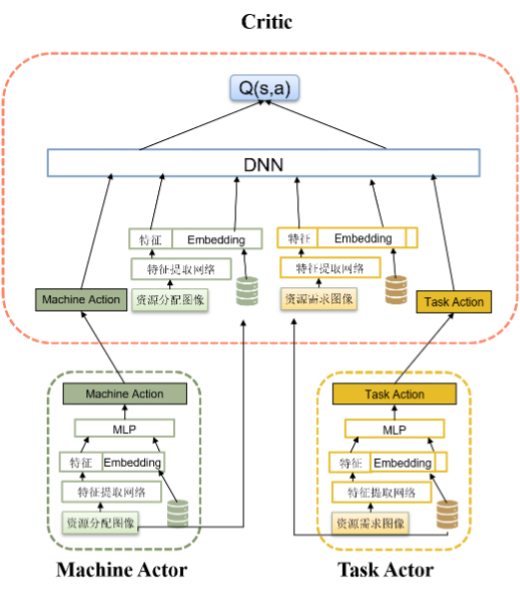
图 1 双智能体模型(DAS)结构
具体的,在任务侧和机器侧各构建出一个智能体,任务侧智能体的状态输入是每个任务的资源需求、任务偏好等任务属性,机器侧智能体的输入是每台机器的当前状态。任务侧的智能体和机器侧的智能体各产生一个动作向量,根据这两个向量的匹配程度(即该机器是否能够提供该任务运行所需资源)进行打分,得到<机器,任务,得分>三元组,其中得分的高低决定了任务部署的优先级。双智能体模型采用多智能体深度确定性策略梯度算法(MADDPG),任务侧智能体和机器侧智能体的Actor网络是独立的,但是共享一个集中式的Critic网络。
2.2 流处理任务资源调度算法
在工业集群中,流任务也是一类应用非常广泛的计算任务,对流任务进行资源管理面临着动态负载建模、高效资源管理决策等问题。本课题组针对流任务的资源管理设计了一种基于强化学习的细粒度资源自动伸缩器,其被命名为SURE。
本课题组设计了一种新颖的时空图表示方法,该时空图可以同时建模流任务的拓扑依赖关系和动态负载。如图2所示,我们形式化的建模了马尔科夫决策过程,为使用强化学习进行资源调度提供了可行性。
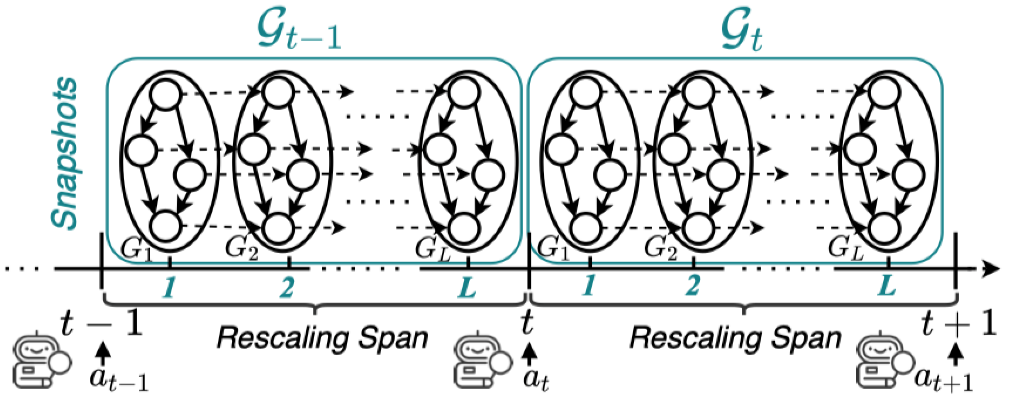
图 2 流计算任务资源自动伸缩的马尔科夫决策过程形式化表示
我们的目标是最大化强化学习奖励,即最小化延迟和最大化资源利用率。延迟和资源利用率这两个指标的权重可以根据实际应用场景进行调整,这保证了设计的资源自动伸缩器可以适应于具有不同计算特点的流任务。
为了高效学习大规模时空图,本课题组设计了一种时空子图采样的算法。对于每个任务节点,我们采样一个保留着完整时空图中最具有代表性信息的时空子图,通过只学习该子图来代替对完整时空图的学习,可以有效减少决策推理的时间。图3为模型的整体架构图。
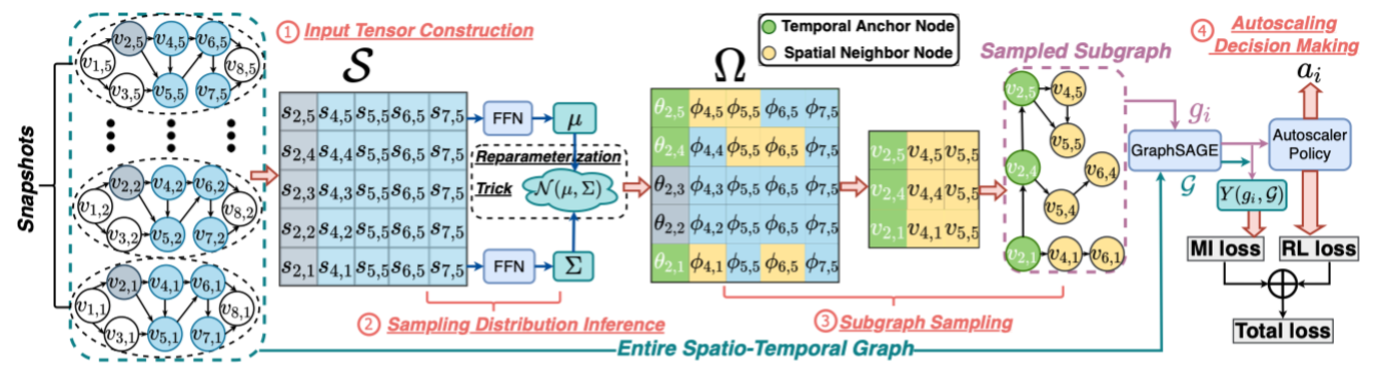
图 3 模型整体结构图
在获取到采样的子图后,我们使用了GraphSAGE来学习子图表示,从而作为任务节点的状态表示。进一步的,考虑到互信息可以用来衡量两个变量之间的相互依赖关系,互信息较大则表明两个变量之间更加具有相关性。因此,我们提出了下面的目标函数:

接下来,我们使用REINFORCE算法来优化自动伸缩器的策略。
3 实验分析
3.1 批处理任务资源调度算法结果分析
为了验证本项目所提出方法的有效性,我们用阿里巴巴的数据集进行了实验。每个时间单位的长度定为一秒,视野长度T定为40,即每次调度时向前看40个时间单位。我们测试了三种集群规模:10台(小规模)、20台(中等规模)、100台机器(大规模)。我们选择了几种常用的启发式算法做为比较的对象:任务调度使用先进先出算法(FIFO)和短作业优先算法(SJF),任务装箱使用首先适应算法(First Fit)和最佳适应算法(Best Fit)。当调度算法同时考虑多种资源时(比如CPU和内存),最佳适应算法只能保证在其中一种资源维度上是最佳的适应(比如CPU)。此外,我们还采用了专门针对多维度资源调度而设计的Tetris算法做为基线。该算法通过计算任务所需资源向量与机器空闲资源向量的点积来确定任务和机器的匹配程度,从而产生调度动作。
图2显示出DAS算法在平均任务延迟率上明显优于启发式算法。从图中可以看出,基于最短任务优先(SJF)的启发式算法效果明显优于其它启发式算法(包括Tetris),但是仍然没有DAS算法的效果好。这是因为平均延迟率这个指标在很大程度上会偏向短任务,因此优先运行短任务是降低平均延迟率的关键,这也是SJF算法具有天然优势的原因。双智能体的DAS算法全面考虑所有机器和任务,同时优化任务执行顺序和任务装箱,在各种规模的集群中都能学习到好的策略。
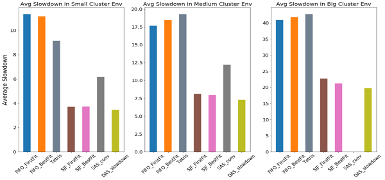
图 4 双智能体模型在平均任务延迟率上的优势
图3测试了双智能体模型对机器属性和任务偏好的支持。图中的四组实验机器属性和任务偏好的标签不断增多:setting1中没有任何标签,settings2、3、4中最大标签数目分别是2、6、10。图中的结果显示考虑了机器属性和任务偏好的启发式算法(FIFO_Weighted 和JCF_Weighted)的平均完成时间显著优于没有考虑这些标签的算法,这说明支持任务对偏好的设置是很重要的。该图同时也显示出双智能体模型在各种场景下都能取得很好的效果。
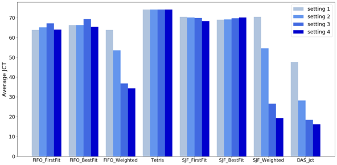
图 5 双智能体模型对任务偏好的支持
3.2 流处理任务资源调度算法结果分析
为了验证方法的有效性,我们也采用阿里巴巴的集群数据集作为任务数据集,不同的是,我们关注长时间运行的流任务,因此,我们仅保留数据集中运行时长超过2000分钟的任务。我们采用Clarknet Trace作为负载数据集,其描述了服务器在一段时间内收到的HTTP请求的数量。为了对比我们的方法在不同大小任务上的效果,我们在任务数据集中采样了6个任务,并分为三组:Small-1,Small-2;Medium-1,Medium-2;Large-1,Large-2。为了和我们的方法做对比,我们选用了三组基线方法:基于启发式的资源自动伸缩器(Heuristic-based autoscaler),即HPA;基于强化学习的资源自动伸缩器(RL-based autoscaler),包括DeepWave,DREAM和TVW-RL;时空图神经网络(Spatio-temporal GNNs),包括ASTGCN和CCRNN。
如表1所示,基于强化学习方法的资源自动伸缩器相比基于启发式规则的方法在大多数任务上通常可以取得更好的效果。这主要是因为基于强化学习的方法可以针对具体的任务和负载情况进行策略优化,而HPA采用启发式规则的方法,不能很好的适应不同的任务和动态的负载。我们的方法在所有任务上比所有的基线方法都要好,这证明了我们提出的子图采样算法可以抽取代表性子图,其蕴含着完整时空图中的时间和空间关联信息。通过仅仅学习采样到的子图,就可以得到有效的任务表示,并做出好的资源伸缩决策。

表 1 在Small,Medium,Large任务集合上的效果对比,其中最好,次好,第三好的效果分别用粗体,下划线,灰色单元格来标注
我们方法的一个重要贡献是提出了一种新颖的子图采样方法,可以有效减少模型推理的时间,并且取得更好的表现。因此,我们分析采样快照的数量k_1对Large-1任务的决策推理时间和奖励的影响。如图6所示,我们的模型可以取得比最好的基线方法CCRNN更好的效果。另外可以看到我们方法的推理时间要少于CCRNN,当k_1增加时,推理时间也在增加,这是因为学习更多的快照会带来更大的计算开销。
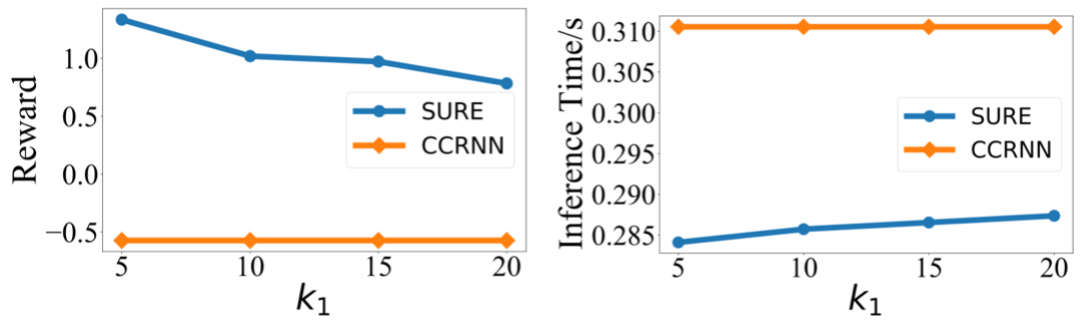
图 6 不同k_1大小对奖励和推理速度的影响
4 总结展望
本课题将深度强化学习技术应用到集群调度领域,通过定义奖励函数自适应地学习出比人工设计更好的调度算法,当环境发生变化时,只需要重新学习就可以适应新环境,大大提高了效率。其中针对批处理任务所实现的调度算法有很好的可扩展性,可以支持集群规模的动态变化;针对流计算任务所实现的资源管理算法可以进行细粒度的资源管理,同时取得较快的决策速度。两个资源管理算法在多项重要指标上都取得了优于传统启发式算法的性能。未来我们将会探索更加有效的集群任务建模方法,设计更加高效的强化学习算法,进一步提高资源调度的效率。
相关成果
论文
1. Mingzhe Xing, Hangyu Mao, Zhen Xiao. Fast and Fine-grained Autoscaler for Streaming Jobs with Reinforcement Learning. International Joint Conference on Artificial Intelligence (IJCAI 2022), July 2022.
2. Pengze Li, Lichen Pan, Xinzhe Yang, Weijia Song, Zhen Xiao and Ken Birman. Stabilizer: Geo-Replication with User-defined Consistency. IEEE 42st International Conference on Distributed Computing Systems (ICDCS 2022), July 2022.
3. Zhenxing Hu and Zhen Xiao. Dino: A Block Transmission Protocol with Low Bandwidth Consumption and Propagation Latency. Proc. of IEEE Infocom (INFOCOM 2022), May 2022.
4. Mingzhe Xing, Ziyun Wang, Zhen Xiao. Analysis of Resource Management Methods Based on Reinforcement Learning. In 2021 International Conference on High Performance Big Data and Intelligent Systems (HPBD&IS 2021), December 2021.
5. Mingzhe Xing, Shuqing Bian, Wayne Xin Zhao, Zhen Xiao, Xinji Luo, Cunxiang Yin, Jing Cai, Yancheng He. Learning Reliable User Representations from Volatile and Sparse Data to Accurately Predict Customer Lifetime Value. ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2021) , August 2021.
6. Hangyu Mao, Zhengchao Zhang, Zhen Xiao, Zhibo Gong, and Yan Ni. Learning Multi Agent Communication with Double Attentional Deep Reinforcement Learning. Journal of Autonomous Agents and Multi-Agent Systems (JAAMAS 2020), March 2020.
7. Hangyu Mao, Zhengchao Zhang, Zhen Xiao, Zhibo Gong, and Yan Ni. Learning Agent Communication under Limited Bandwidth by Message Pruning. Proc. of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), February 2020.
8. Hangyu Mao, Wulong Liu, Jianye Hao, Jun Luo, Dong Li, Zhengchao Zhang, Jun Wang, and Zhen Xiao. Neighborhood Cognition Consistent Multi-Agent Reinforcement Learning. Proc. of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI 2020), February 2020.
专利
基于强化学习和任务感知随机游走的深度学习任务调度方法和系统 发明人:邢铭哲、肖臻,专利号:202211398671.9,申请日期:2022年11月9日
基于多智能体深度强化学习的集群资源调度方法及系统 发明人:潘丽晨,毛航宇,肖臻,张正超,专利号:202010322543.0,申请时间:2020年4月22日
软件著作权
软件全称:基于深度强化学习的集群调度系统[简称: RLScheduler]V1.0 登记号:2020SR1178387 著作权人:北京大学 登记日期:2020年7月20日